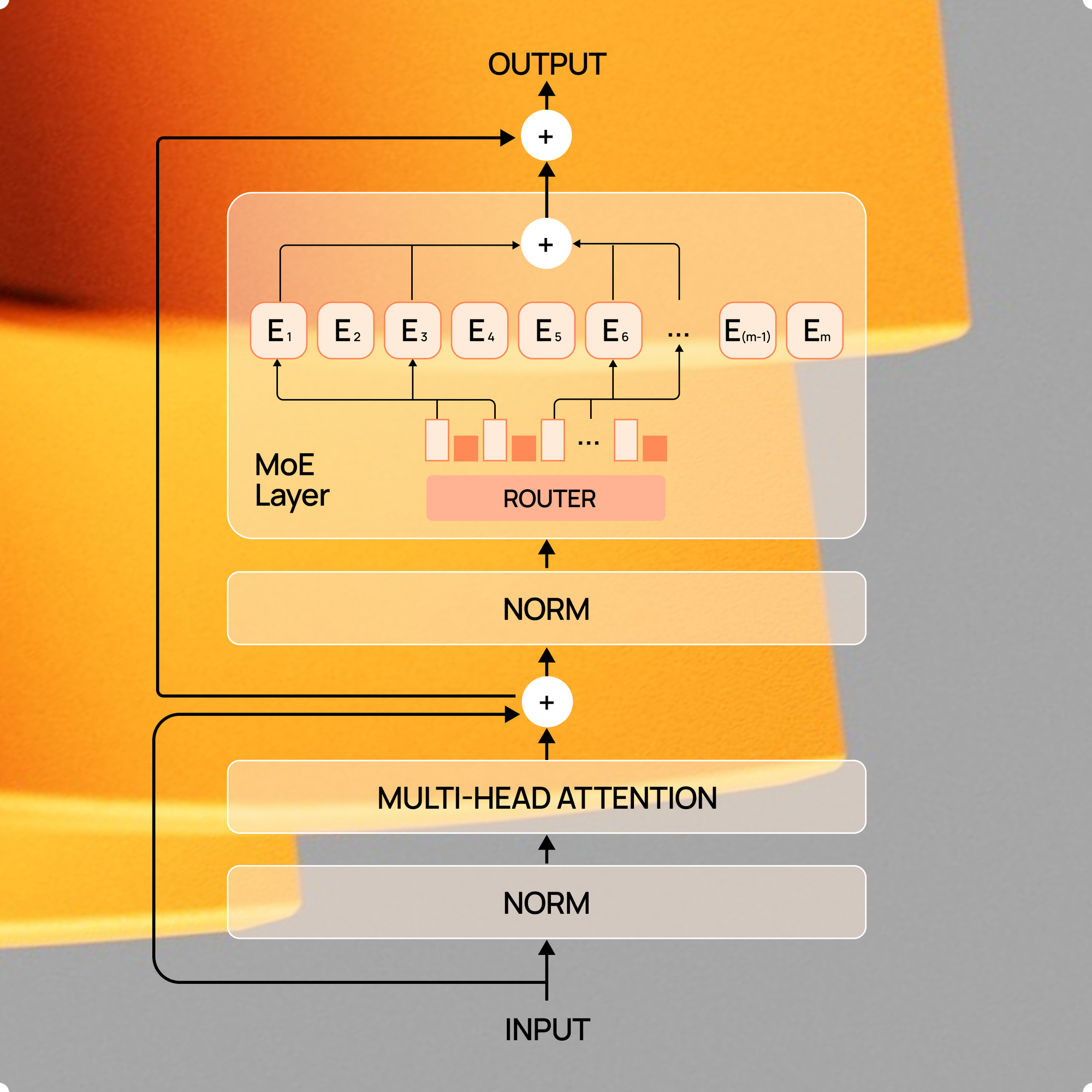
The MoE 101 Guide:
From Theory to Production
This series teaches you how to build MoE systems that work. We’ll cover the fundamentals, routing strategies, training gotchas, scaling math, and hardware. By the end, you will implement production MoE models – not just read about them in papers.