
Whitepapers
October 17, 2025
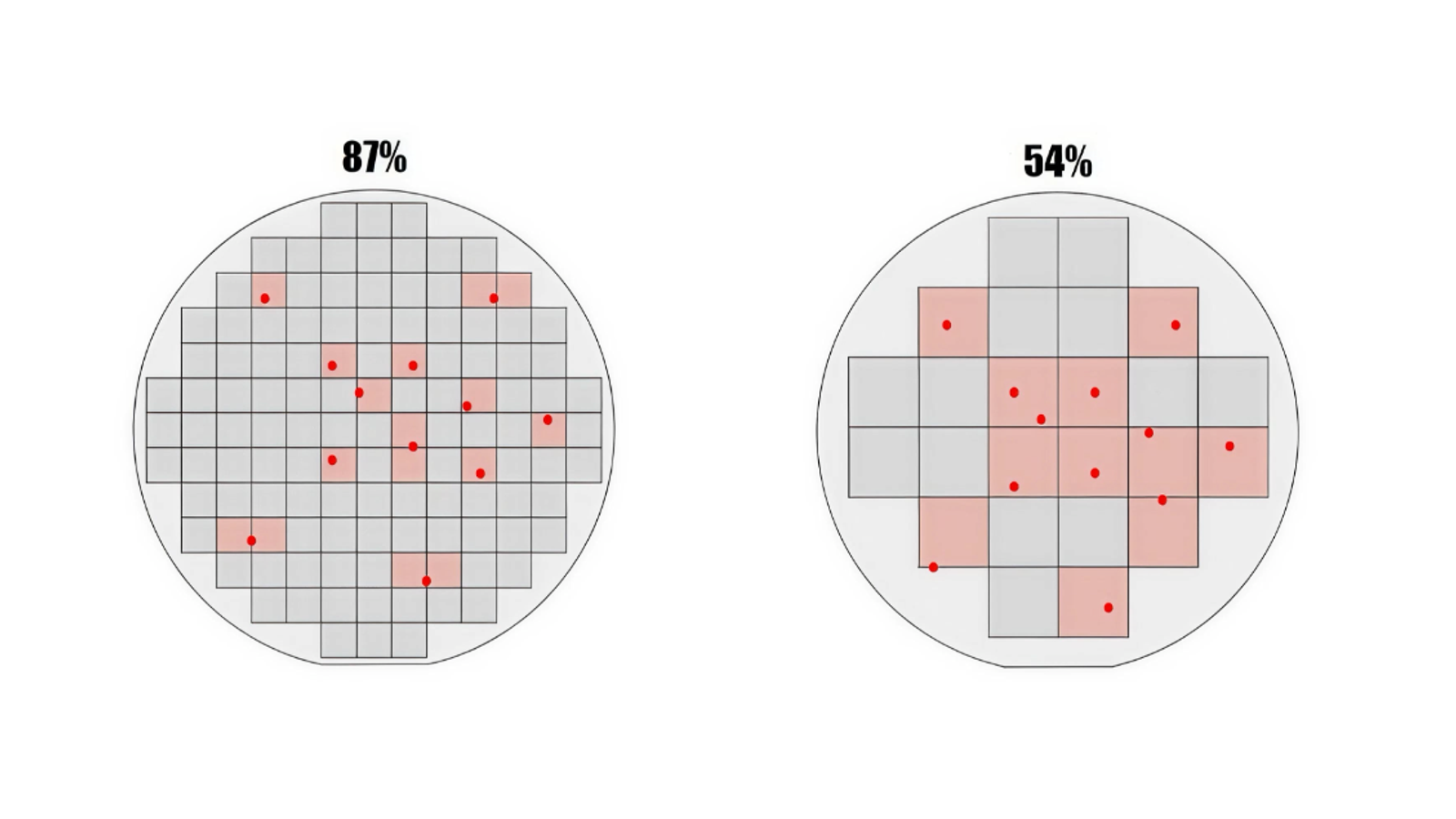
How Cerebras Solved the Wafer-Scale Yield Challenge
Cerebras created the world’s first wafer-scale processor, solving the yield problem that prevented large monolithic chips for over half a century. By designing for—rather than merely trying to avoid—defects, Cerebras achieves more than 100x higher fault tolerance across a full 300 mm wafer compared to a much smaller GPU. This breakthrough redefines computing for AI and HPC—enabling faster training of frontier models, real-time inference for intelligent applications, and step-change advances in scientific computing.
October 17, 2025
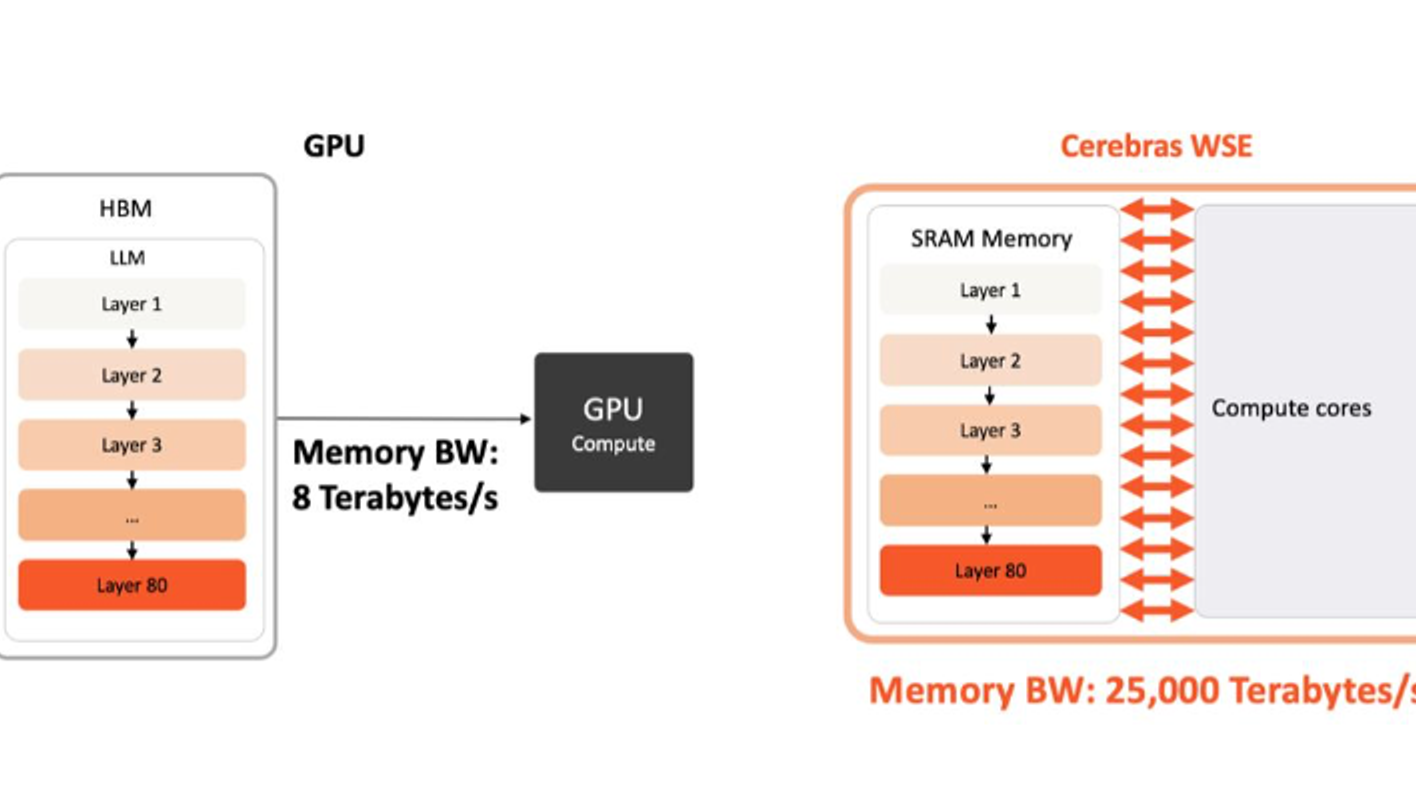
Cerebras Inference: Build Products that Others Can’t with the Fastest AI Infrastructure
Advanced reasoning, agentic, long‑context, and multimodal workloads are driving a surge in inference demand—with more tokens per task and tighter latency budgets—yet GPU‑based inference is memory‑bandwidth bound, streaming weights from off‑chip HBM for each token and producing multi‑second to minutes-long delays that erode user engagement. Cerebras Inference shatters this bottleneck through its revolutionary wafer-sized chip architecture, which uses exponentially faster memory that is closer to compute, delivering frontier‑model outputs at interactive speed. This whitepaper explains the inference imperative, GPU limits, introduces the Wafer‑Scale Engine, and presents head‑to‑head results vs. Nvidia Blackwell B200 on speed, accuracy, price‑performance, and energy efficiency; it then discusses deployment readiness, maps these results to real‑world use cases and outlines deployment options from serverless to on‑premises. Finally, this paper discusses the road ahead for Cerebras inference and how to start building products that others can’t.

October 17, 2025
Cerebras Wafer-Scale Cluster
The compute and memory demands for deep learning and machine learning (ML) have increased by several orders of magnitude in just the last couple of years, and there is no end in sight. Traditional improvements in processor performance alone struggle to keep up with the exponential demand. A new chip architecture co-designed with the ML algorithms can be better equipped to satisfy this unprecedented demand and enable the ML workloads of the future. This article describes the Cerebras architecture and how it is designed specifically with this purpose, from the ground up, as a wafer-sized chip to enable emerging extreme-scale ML models. It uses fine-grained data flow compute cores to accelerate unstructured sparsity, distributed static random-access memory for full memory bandwidth to the data paths, and a specially designed on-chip and off-chip interconnect for ML training. With these techniques, the Cerebras architecture provides unique capabilities beyond traditional designs.
October 17, 2025
Training Large Language Models on Cerebras Wafer Scale Engine
State-of-the-art language models are extremely challenging to train; they require huge compute budgets and complex distributed compute techniques. As a result, few organizations train large language models (LLMs) from scratch. In this paper, we present a new training execution flow called weight streaming. By disaggregating parameter storage from primary compute, weight streaming enables the training of models two orders of magnitude larger than the current state-of-the-art. Because weight streaming runs in strictly data parallel form on Cerebras CS-3, it avoids the complex and time-consuming distributed computing techniques that bedevil ML practitioners. Weight streaming demonstrates near perfect linear scaling across clusters of Cerebras CS-3 systems. We present experimental results showing scaling of large GPT-style large language models across clusters of up to 64 CS-3s, containing 54 million AI cores. We also show how the weight streaming architecture enables the harvesting of dynamic, static, structured and unstructured sparsity.

April 27, 2023
Argonne National Laboratory
At ANL, Cerebras is working with research staff in the Computing, Environment, and Life Sciences (CELS) directorate to accelerate groundbreaking scientific and technical innovation. This partnership has produced award-Winning work, spanning cancer treatment, CoVID-19 drug discovery, and advances in physics.
June 06, 2022
Deep Learning Programming at Scale
Deep learning has become one of the most important computational workloads of our generation, advancing applications across industries from healthcare to autonomous driving. But it is also profoundly computationally intensive. (Updated June 2022.)
April 06, 2022
Powering Extreme-Scale HPC with Cerebras WaferScale Accelerators
In this paper, we will explore the challenges facing HPC developers today and show how the Cerebras architecture can help to accelerate sparse linear algebra and tensor workloads, stencilbased partial differential equation (PDE) solvers, N-body problems, and spectral algorithms such as FFT that are often used for signal processing.

February 07, 2022
The Cerebras Software Development Kit: A Technical Overview
Cerebras has introduced a new software development kit (SDK) which allows anyone to take advantage of the strengths of the CS-2 system. Developers can use the Cerebras SDK to create custom kernels for their standalone applications or modify the kernel libraries provided for their unique use cases. The SDK enables developers to harness the power of wafer-scale computing with the tools and software used by the Cerebras development team.

October 05, 2021
Lawrence Livermore National Laboratory
Lawrence Livermore National Laboratory in Livermore, California, is a federal research facility primarily funded by the US Department of Energy Energy’s National Nuclear Security Administration (NNSA). LLNL’s mission is to strengthen the United States’ security by developing and applying world-class science, technology and engineering.

April 06, 2021
Cerebras Systems: Achieving Industry Best AI Performance Through A Systems Approach
The CS-2 is a system solution that consists of innovations across three dimensions: a) the second generation Cerebras Wafer Scale Engine (WSE-2) — the industry’s largest and only multi-trilliontransistor processor, b) the Cerebras System and c) the Cerebras software platform.