inference
CLOUD
Get instant access to inference that’s up to 15x faster than NVIDIA GPUs — build more interactive, intelligent products across coding, research, voice, automation, and more agentic use cases.
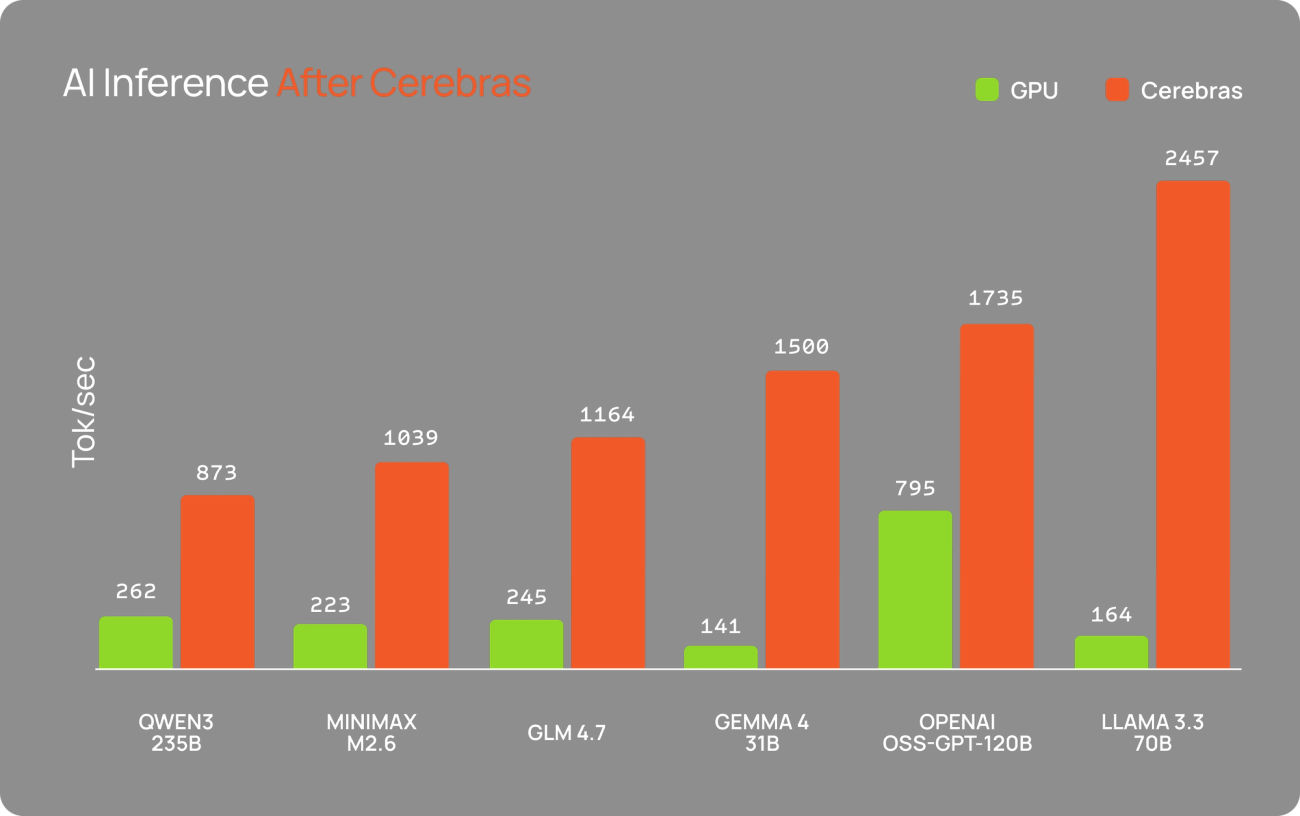

Unmatched Speed in Action
Watch Cerebras deliver top quality answers in a fraction of the time it takes GPUs.
Gemma-4-31B
Multimodal document analysis
Kimi K2.6
Financial Dashboard Generation
GLM 4.7
Create a pool game in HTML
Codex-Spark
Create a Salesforce clone
Gemma-4-31B
Multimodal document analysis
Kimi K2.6
Financial Dashboard Generation
GLM 4.7
Create a pool game in HTML
Codex-Spark
Create a Salesforce clone

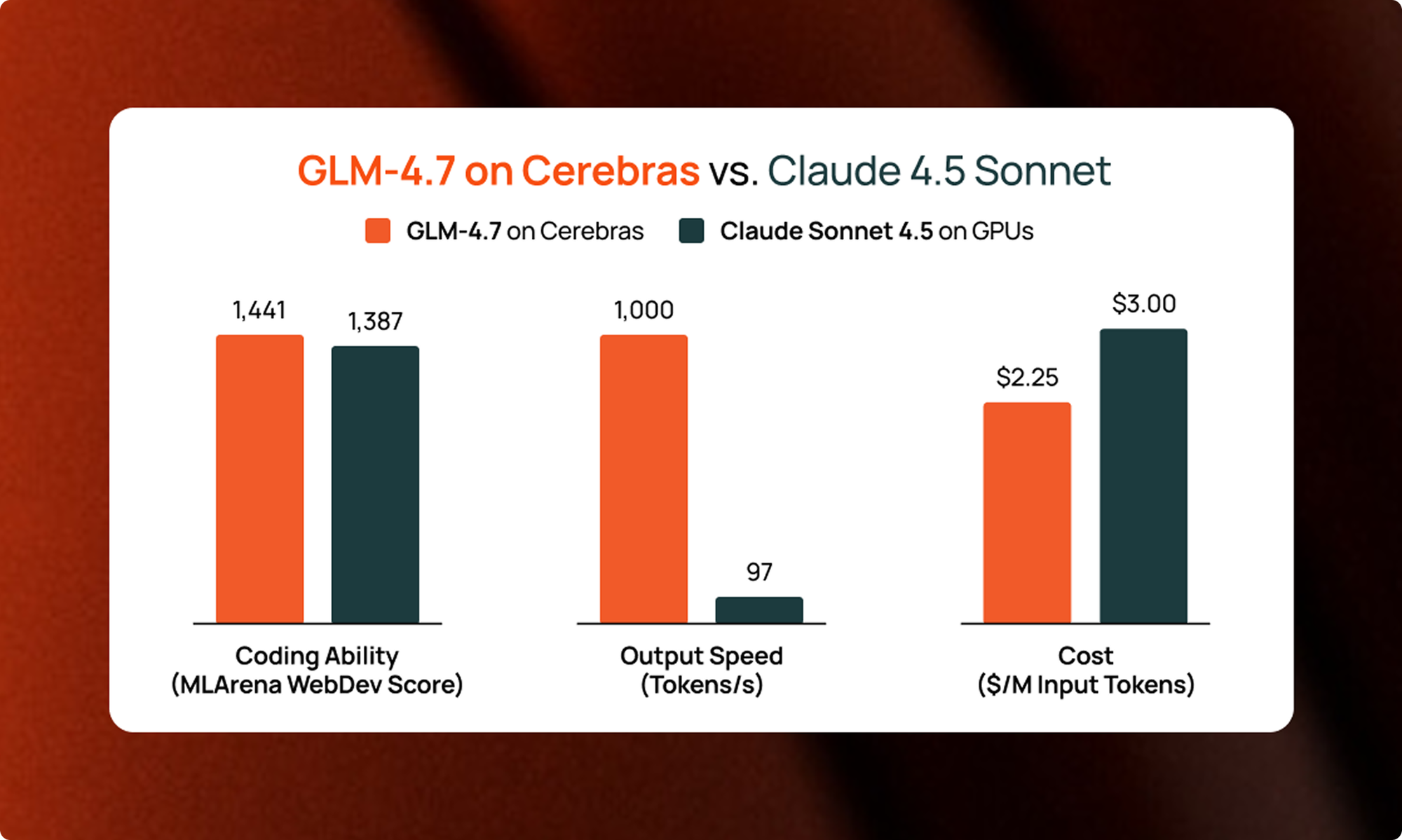

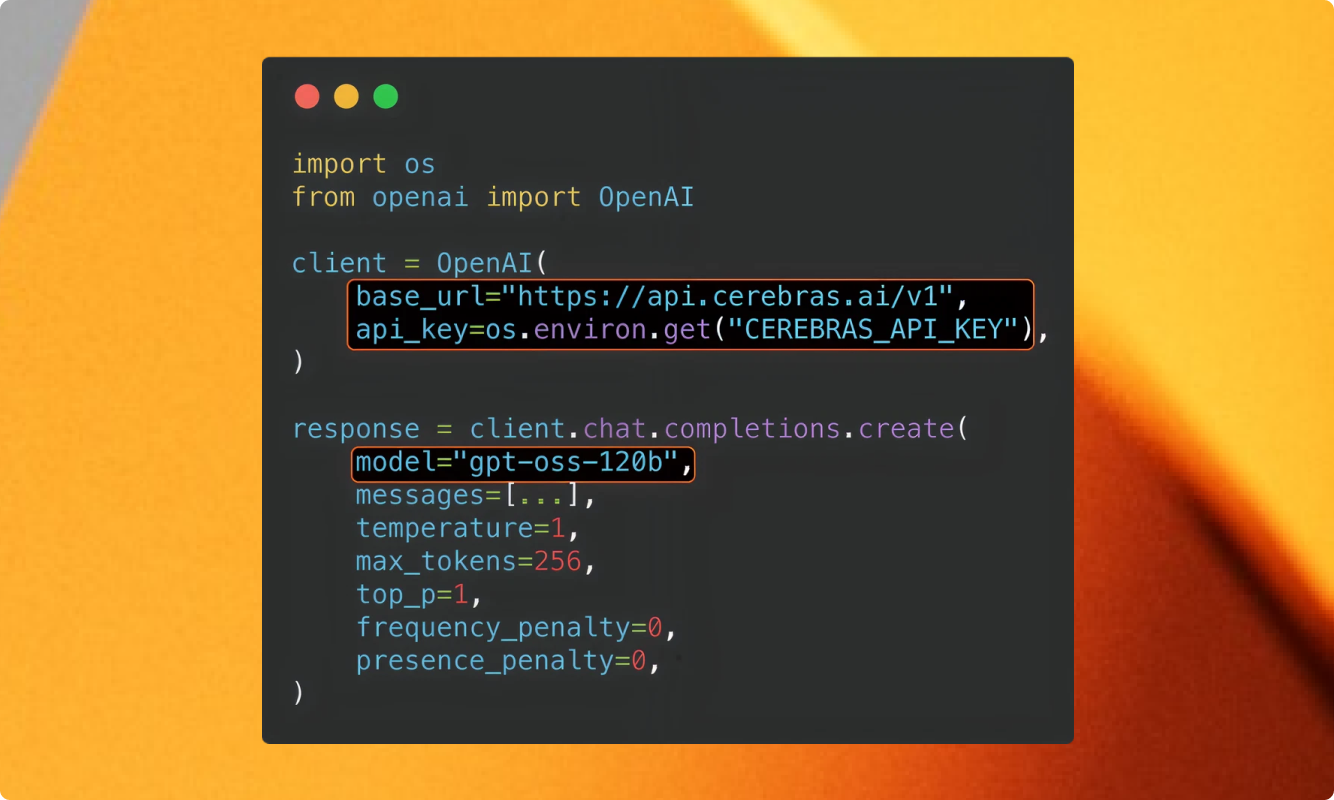
Straightforward Pricing
Cerebras Inference offers flexible, transparent pricing
designed for everyone—from startups to global enterprises.
Free Trial
Get started with $5 in free credit after creating an account. Prototype prompts, agents, and real-time apps before you spend a dollar.
Developer
Self-serve pay-per-token pricing for higher-volume builders. Add funds starting at $10, get 10x higher rate limits than Free, and run with higher priority processing.
Enterprise
Production-scale inference for high-volume applications. Get the highest throughput, dedicated queue priority, custom model weights, uptime guarantees, and dedicated support.




Customer Stories
"With Cerebras’ inference speed, GSK is developing innovative AI applications, such as intelligent research agents, that will fundamentally improve the productivity of our researchers and drug discovery process."
"DeepLearning.AI has multiple agentic workflows that require prompting an LLM repeatedly to get a result. Cerebras has built an impressively fast inference capability which will be very helpful to such workloads."
"We’re excited to share the first models in the Llama 4 herd and partner with Cerebras to deliver the world’s fastest AI inference for them, which will enable people to build more personalized multimodal experiences. By delivering over 2,000 tokens per second for Scout – more than 30 times faster than closed models like ChatGPT or Anthropic, Cerebras is helping developers everywhere to move faster, go deeper, and build better than ever before."
"For traditional search engines, we know that lower latencies drive higher user engagement and that instant results have changed the way people interact with search and with the internet. At Perplexity, we believe ultra-fast inference speeds like what Cerebras is demonstrating can have a similar unlock for user interaction with the future of search - intelligent answer engines."

By partnering with Cerebras, we are integrating cutting-edge AI infrastructure […] that allows us to deliver the unprecedented speed, most accurate and relevant insights available – helping our customers make smarter decisions with confidence.
