May 15 2025
Realtime Reasoning is Here - Qwen3-32B is Live on Cerebras
Qwen3-32B on Cerebras runs at 2,400 tokens/s, making reasoning run in realtime
We’re excited to announce that Alibaba Qwen3-32B is now available on Cerebras. Qwen3-32B is a world-class model with comparable quality to DeepSeek R1 while outperforming GPT-4.1 and Claude Sonnet 3.7. It excels in code-gen, tool-calling, and advanced reasoning, making it an exceptional model for a wide range of production use cases.
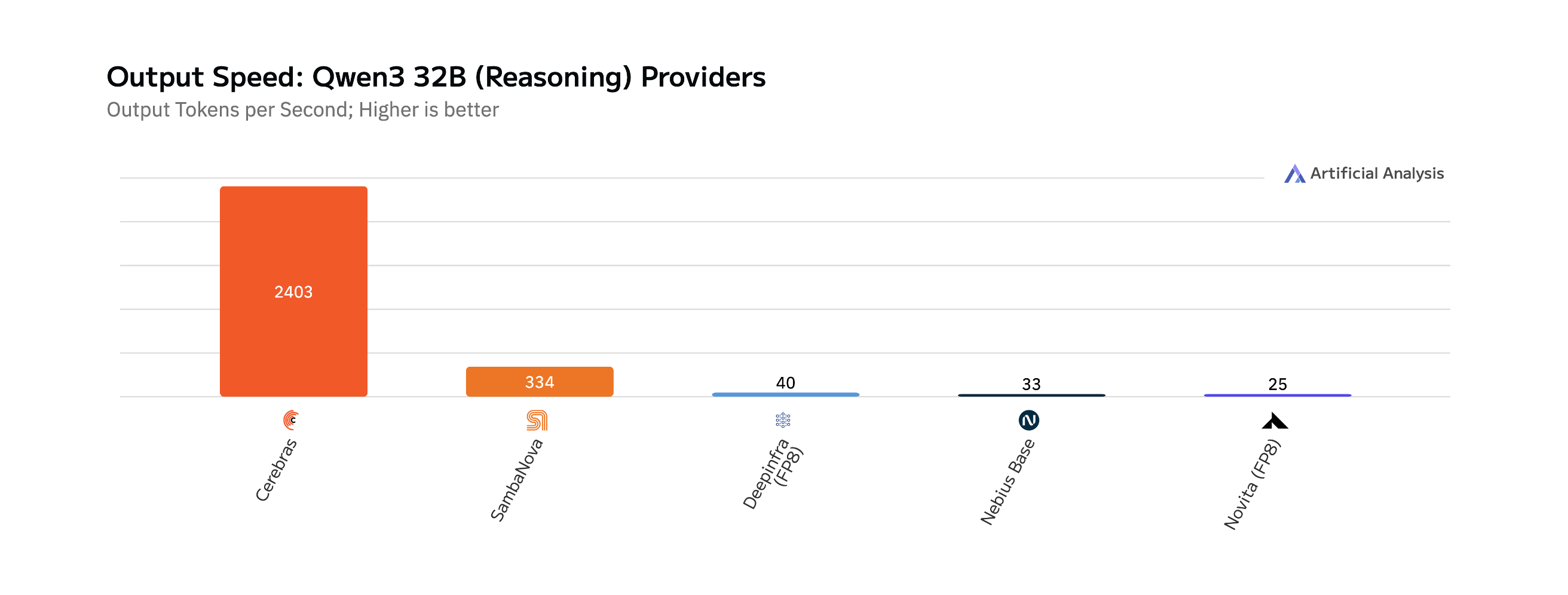
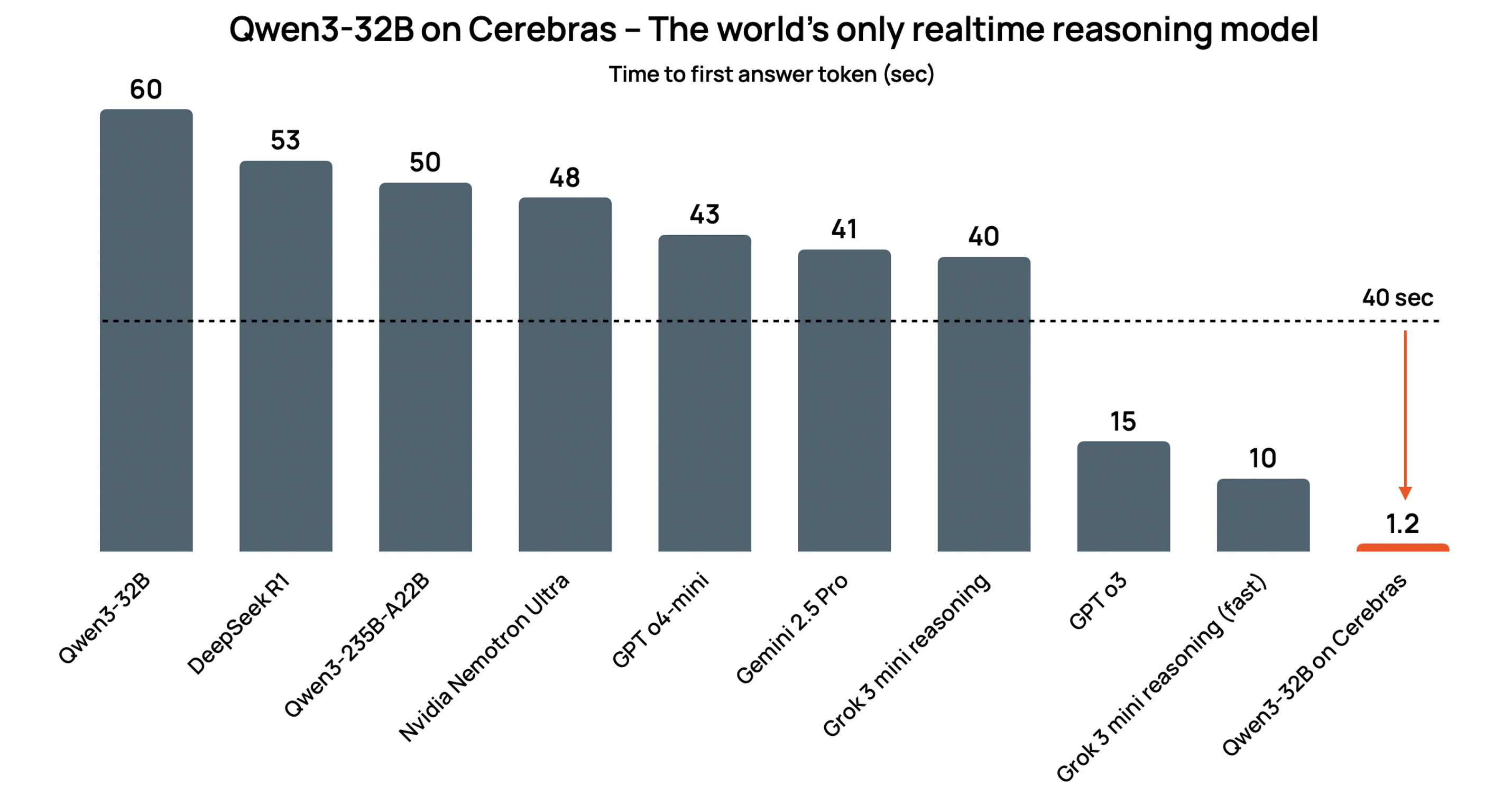
Reasoning models such as Qwen3-32B can take over a minute to return an answer. Thanks to the incredible speed of the Cerebras Wafer Scale Engine, we can return the first answer token in just 1.2 seconds, as measured by Artificial Analysis. In addition, we achieve an unprecedented 2,400 token/s output speed – over 40x faster than the best GPU result. This makes Qwen3-32B not only one of the world’s most powerful models, but the only reasoning model that can run in real time when using Cerebras.
Run Reasoning in Realtime on Cerebras
One of the biggest constraints of reasoning model adoption is output speed. Every GPU based inference API tops out at 150 tokens per second. This may be sufficient for general chat, but becomes a bottleneck for agents, code-generation, or any system requiring multiple steps of reasoning and tool use. Deep Research – a popular agentic search flow used in ChatGPT, Perplexity, and others can take minutes to return an answer vs. a second using Google search.
Qwen3-32B on Cerebras runs at 2,400 tokens/s, making reasoning run in realtime. This means unlike o3 or R1 where reasoning must be used sparingly in specific use-cases that can tolerate multi-minute latency, Qwen3-32B on Cerebras can be used in all use-cases, replacing common GPT-4.1 and DeepSeek endpoints. This lets you build agents that actually feel responsive, perform multi-hop reasoning without delay, and stream code or long-form answers in real time.
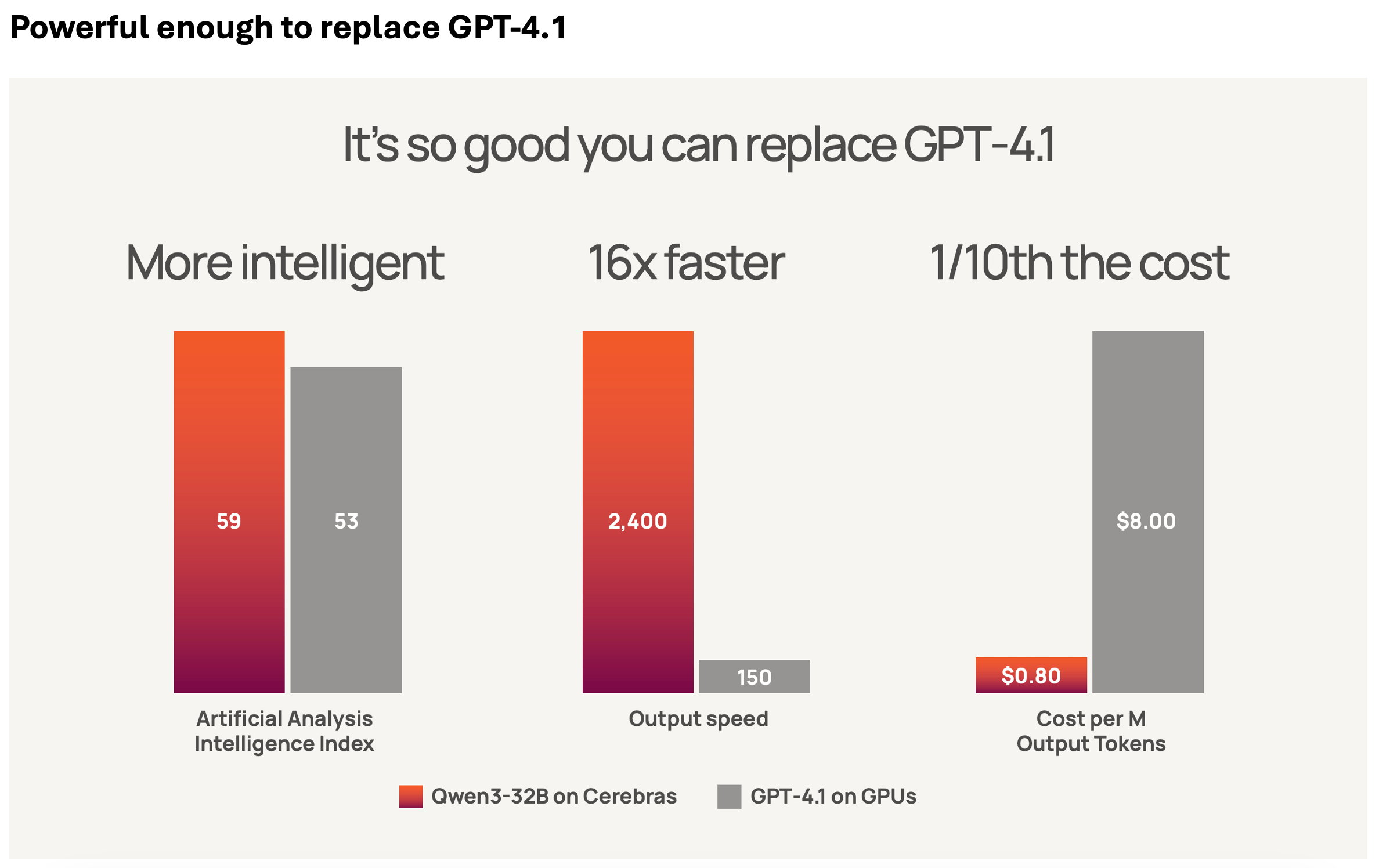
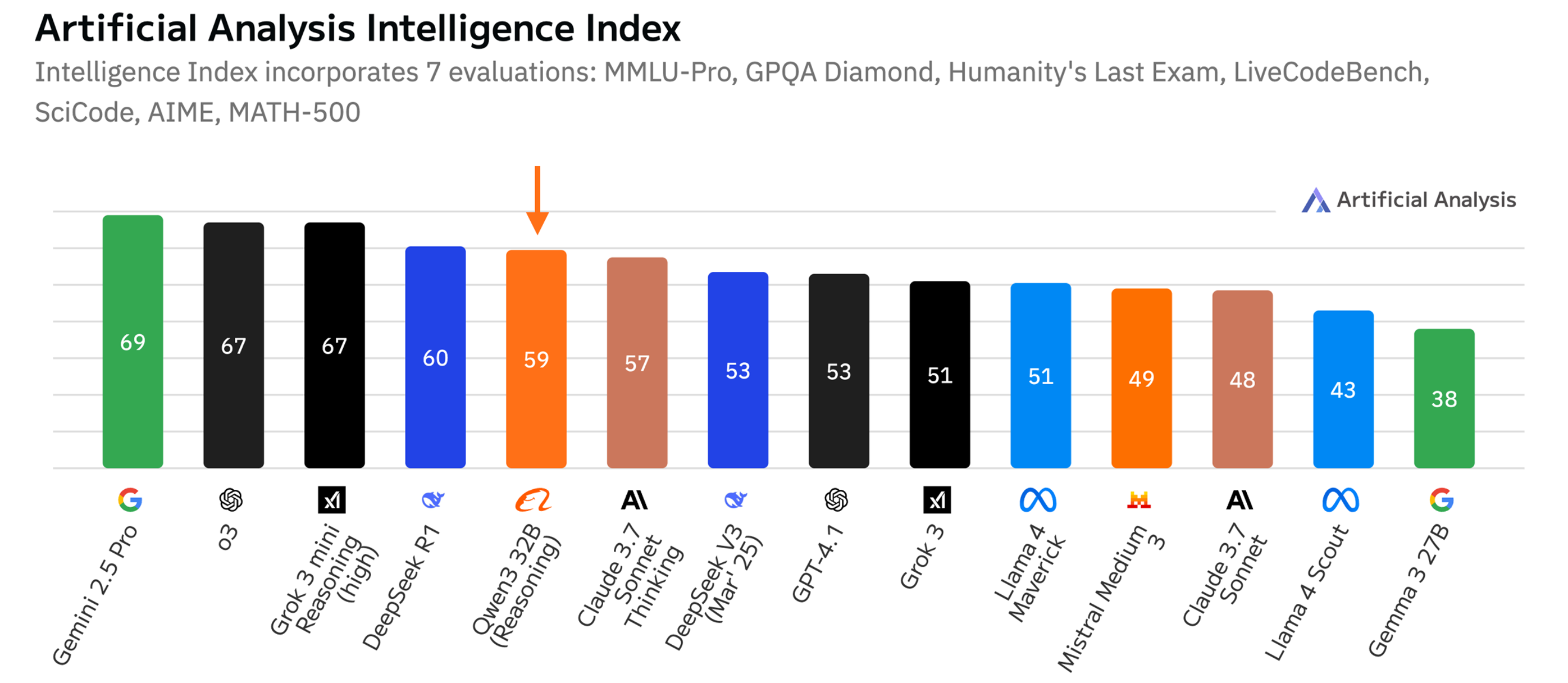
Qwen3-32B is a reasoning-first model that offers some of the highest intelligence scores of any dense model available today—and it does so in a way that makes it an easy and compelling drop-in replacement for GPT-4.1, one of the most widely used AI endpoints in production. On the Artificial Analysis Intelligence Index, which aggregates seven evaluations including MMLU-Pro, GPQA Diamond, LiveCodeBench, and SciCode, Qwen3-32B achieves a blended score of 59, outperforming GPT-4.1’s 53. This is a landmark result, showing a medium-sized reasoning model can exceed the capabilities of a flagship closed model.
In terms of generation speed, the difference is even more striking. According to measurements from Artificial Analysis, GPT-4.1 outputs around 150 tokens per second, while Qwen3-32B on Cerebras delivers 2,400 tokens per second—a 16x speedup. Cerebras generates the first answer token in 1.2 seconds – a first of any reasoning model on any hardware. This matters for every real-time application: reasoning chains, tool use, and multi-step prompts are all gated by token output speed. Qwen3-32B lets you run these workloads at full performance, without latency penalties, for the first time.
Finally, let’s look at cost. Because GPT-4.1 is such a large model, it comes with a price tag to match—$8 per million output tokens, which is prohibitive for many real-world applications. In contrast, Qwen3-32B is so efficient—and runs so fast on Cerebras hardware—that we can offer it at just $0.80 per million output tokens, a full order of magnitude cheaper. This reflects the combined advantage of open-weight reasoning models running on wafer-scale hardware designed for high-throughput inference. The result isa direct drop-in replacement for GPT-4.1 with higher intelligence, faster performance, and a fraction of the cost.
Get Started
Whether you’re using OpenAI, Claude, or an existing Cerebras endpoint, it takes just 30 seconds to switch to Qwen3-32B. You should see equal to higher model intelligence with 16x faster speed and lower cost.
Qwen3-32B on Cerebrasis priced at $0.40 per million input tokens and $0.80 per million output tokens.Qwen3 on API and chat are available now to every developer – no waitlist. On our generous free tier, every developer gets 1 million tokens/day. Start building today!