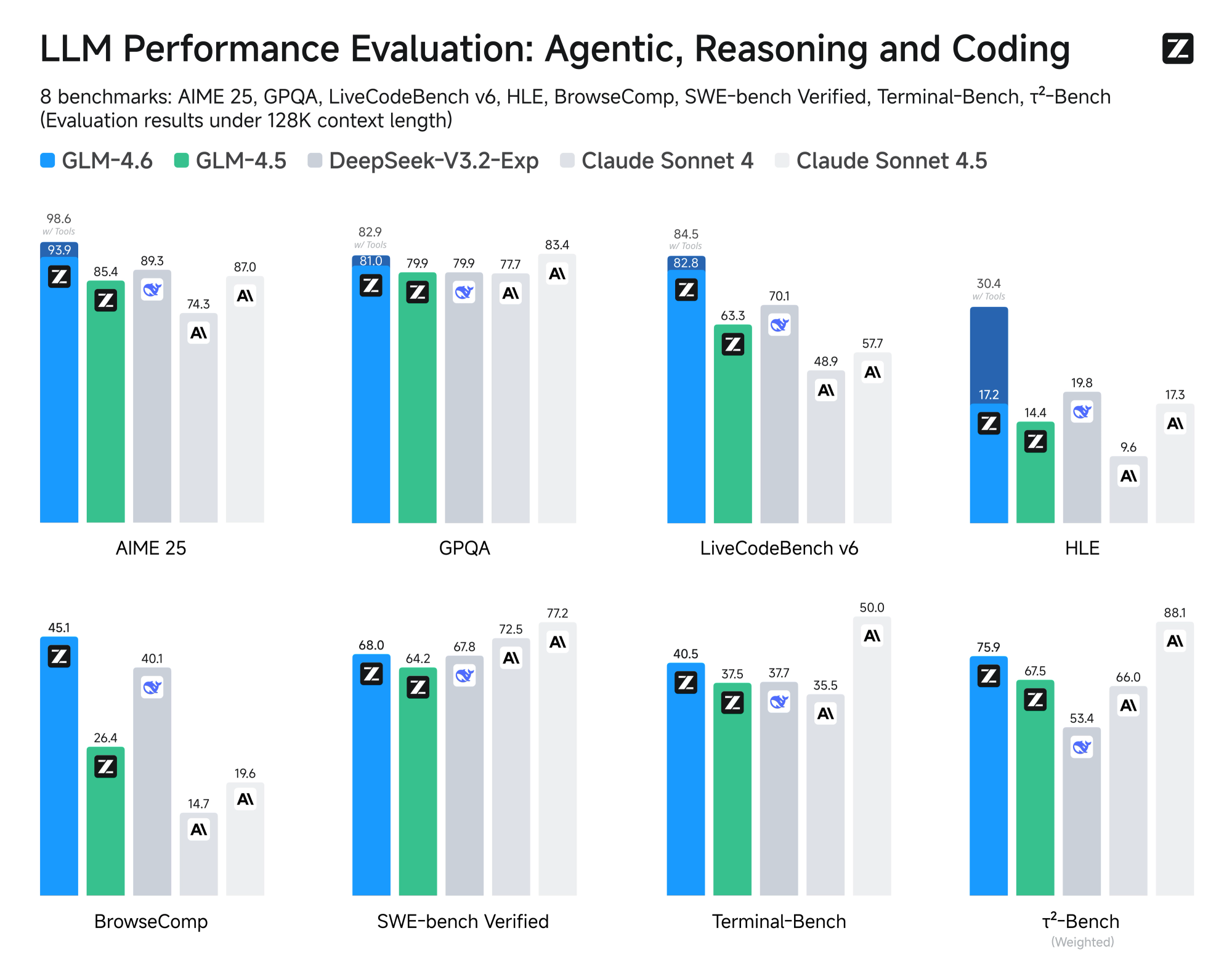
now upgraded with glm 4.6
THE FASTEST WAY TO CODE WITH AI
Stop waiting on your model. Cerebras runs GLM 4.7 — the best-in-class model for code generation, at 1,000 tokens+ per second — so you can stay in flow.
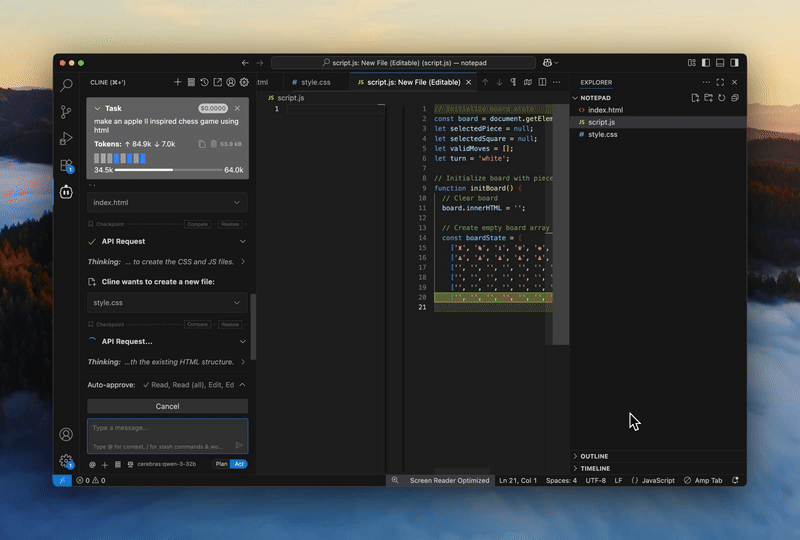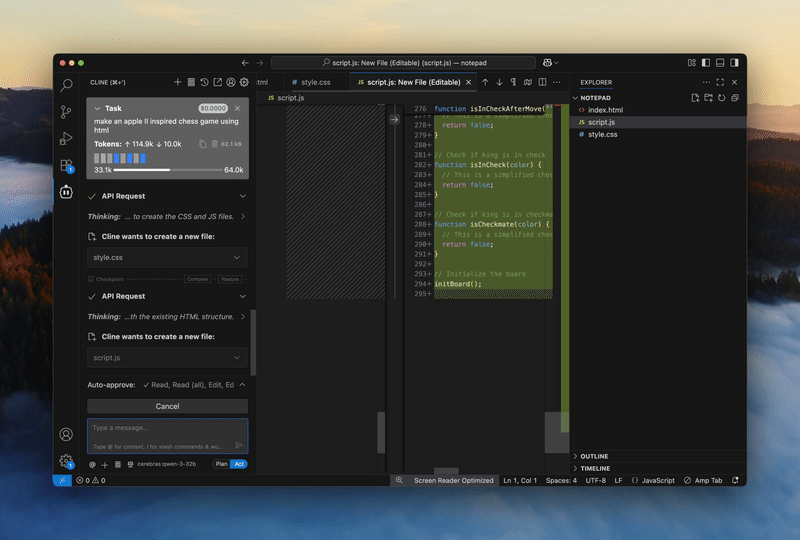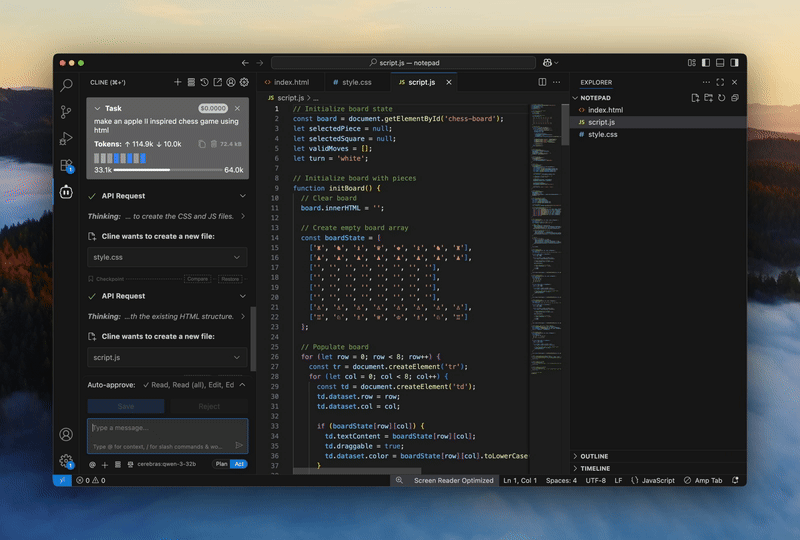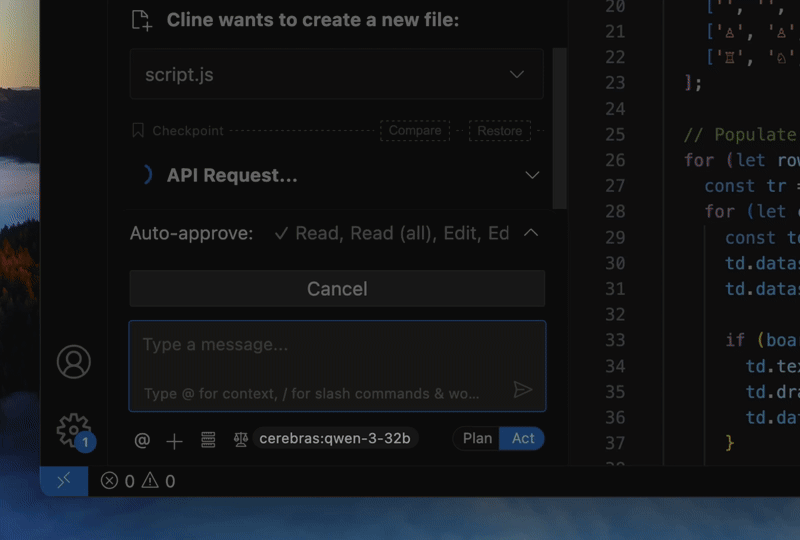
now upgraded with glm 4.6
Stop waiting on your model. Cerebras runs GLM 4.7 — the best-in-class model for code generation, at 1,000 tokens+ per second — so you can stay in flow.
Get Updates
Performance comparisons are based on third-party benchmarking or internal testing. Observed inference speed improvements versus GPU-based systems may vary depending on workload, configuration, date and models being tested.