Jan 28 2026
StackAI × Cerebras: enabling the fastest inference for enterprise AI agents
StackAI is a low-code enterprise platform for building and deploying AI agents in regulated industries, powering workflows like compliance reviews, underwriting, and claims automation. As customers moved from simple copilots to complex, multi-step agentic workflows, StackAI needed an inference layer that could deliver sub-second latency across diverse model sizes and use cases. By integrating Cerebras, StackAI gives enterprises fast, flexible, production-grade inference—so high-stakes workflows like claims triage, compliance checks, and credit decisioning feel instantaneous. Together, StackAI and Cerebras enable real-time, scalable agentic automation across finance, healthcare, and the public sector.
The Challenge
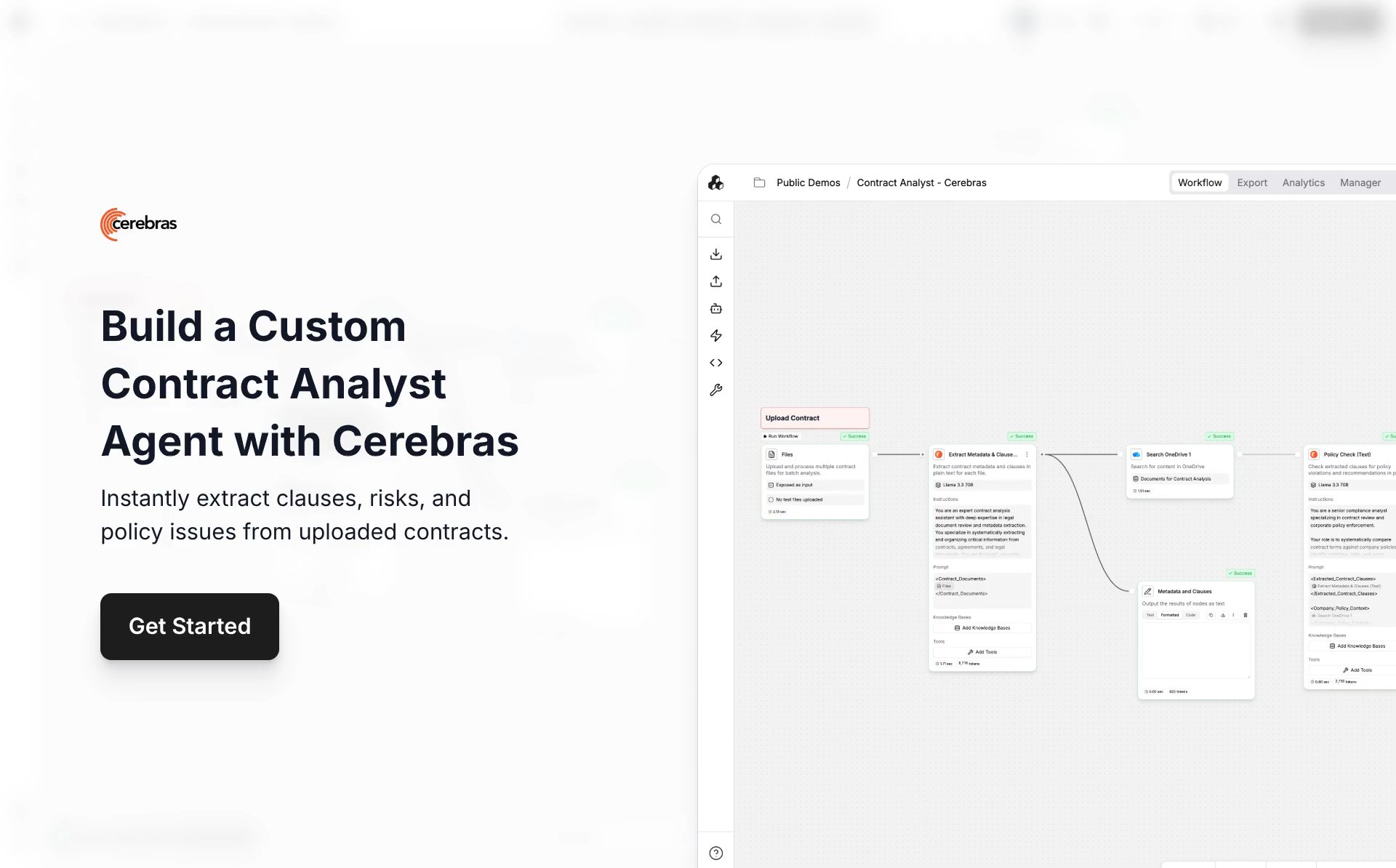
StackAI supports hundreds of use cases, from document-heavy processes to real-time operational decision-making, all on one secure platform, and each is built on structured retrieval, multi-step reasoning, and integrations across dozens of enterprise systems. As demand grew and customers shifted from simple assistants to fully automated workflows, speed and responsiveness became essential to product adoption.
Enterprise agents behave more like distributed systems than chatbots. A single workflow may involve multiple rounds of RAG, tool use, planning, verification, and summarization. Some workloads require deep, multi-hop reasoning over long documents. Others like front-line service chatbots and dashboard-driven insights, require near-instant responses.
As StackAI expanded into more regulated sectors, two requirements stood out:
- Responsiveness
If an agent is embedded inside claims systems, compliance dashboards, or underwriting tools, even small delays break flow and erode trust. - Flexibility
Different workflows require different model families: small models for routing and classification, mid-size models for day-to-day operations, and larger models for difficult reasoning tasks.
To support the breadth of these workloads, StackAI needed a fast, flexible inference foundation that could scale—without forcing their team to manage GPU clusters or compromise on latency or model choice.
The Solution: Fast where it counts, flexible everywhere else
StackAI is designed around enterprise choice. Instead of enforcing a single inference provider or an opaque routing layer, the platform gives enterprises full control over which model and provider power each step of an agent’s workflow. Customers can select from a broad range of open-source models (small models for routing or classification, mid-size models for operational tasks, and larger models for complex reasoning) depending on their cost, performance, and governance requirements.
Cerebras became the clear answer to the speed challenge. Inside StackAI’s flexible, bring-your-own-model framework, Cerebras is the default choice whenever humans are in the loop and waiting—claims triage, compliance checks, credit decisions, exception handling, quality verification, and other latency-sensitive steps. Its ultra-low-latency inference (up to 15x faster than GPU) keeps multi-step, RAG-heavy agent chains feeling instant, so even deep reasoning over long documents lands like a normal UI interaction, not a long-running workflow.
By highlighting Cerebras where it delivers the most user value, StackAI helps enterprises balance speed, cost efficiency, and reasoning depth without locking them into a single inference strategy. StackAI users particularly benefit from Cerebras in:
- Document-heavy reasoning loops where sub-second responses compound across multiple turns
- Planning and orchestration steps that block subsequent actions
- Quality checks, quick classifications, verifications, and routing decisions
- Real-time agent interfaces embedded in dashboards, forms, and operational tools
For workflows where responsiveness drives adoption, Cerebras ensures that StackAI’s agents behave like high-speed operational systems rather than slow, sequential scripts.
The Experience: Feeling the speed
For end customers, having access to the fastest inference on the planet changes how agents are used, and how often. Enterprises building on StackAI report that when response times drop into “instant” territory, engagement increases across both operational and knowledge-worker teams. Compliance staff run more reviews in real time. Claims teams get immediate synthesis instead of waiting for long-running workflows. Underwriters receive instant policy checks and exception memos. Legal teams can trigger iterative redline reviews without losing momentum. Internally, StackAI observed:
- Up to 50% reductions in latency across multi-step workflows
- Up to 10x improvements in throughput stability during surge periods
- Up to 20–35% lower workflow-level inference costs through flexible routing
- Faster task completion across customer-facing automations
Scaling fast inference across enterprises
As StackAI expands across industries with strict security and procurement requirements, the ability to deploy Cerebras inference in flexible, enterprise-ready environments has become essential. Cerebras’ support for private deployments, hybrid setups, and secure API integration allows StackAI to serve customers in finance, healthcare, and government without requiring new procurement paths or GPU infrastructure.
With Cerebras, any enterprise using StackAI can access real-time, production-grade inference performance, whether embedded in complex multi-agent orchestrations or powering interactive, user-facing workflows.
See how StackAI fits in Cerebras’ fast growing ecosystem.